The AI4Life Model Evaluation Platform: building bridges between the BioImage Archive and the BioImage Model Zoo
by Teresa Zulueta-Coarasa
The growing number of models available at the BioImage Model Zoo, are a valuable resource for life scientists aiming to analyze complex imaging data using AI. However, users can struggle to identify which model best matches their own data. At the same time, model developers frequently lack access to diverse datasets, limiting their ability to evaluate how well their models generalize across different biological imaging scenarios.
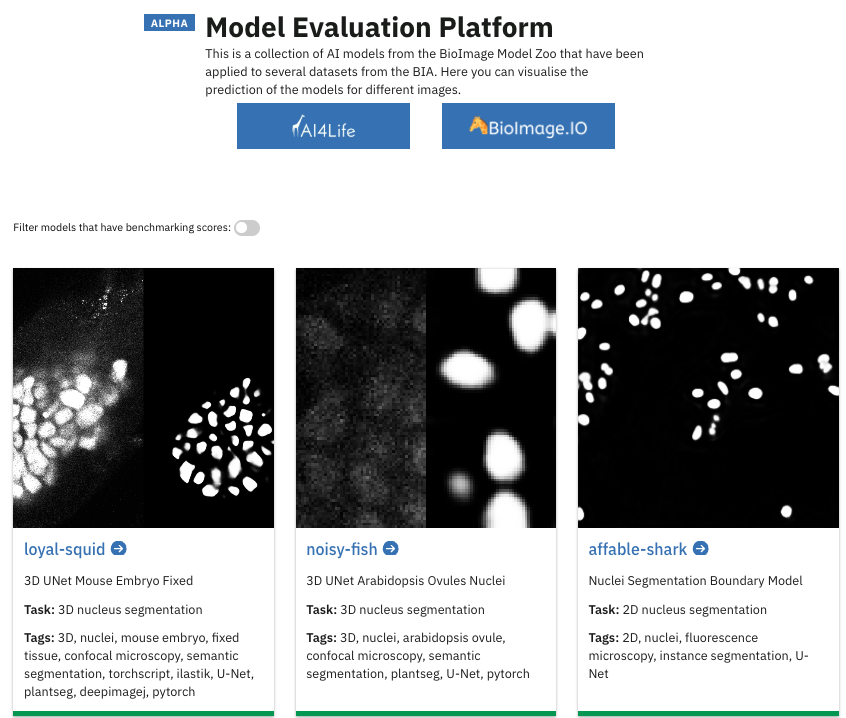
To address both challenges, we have developed the Model Evaluation Platform which provides side-by-side performance comparisons of different models on a wide variety of imaging datasets from the BioImage Archive.
The platform offers two complementary ways to explore model performance. In the model-centric view (“Model Evaluation Platform”), you can compare how a single model performs across a wide range of datasets. This is especially useful for model developers, who can assess how their contributions to the BioImage Model Zoo generalise across diverse imaging data. Alternatively, the dataset-centric view (“Analysed Datasets”) allows you to examine how different models perform on the same dataset. This perspective is ideal for life scientists, who can identify datasets similar to their own and discover which models are likely to yield the most relevant results for their research. This dual approach makes it easier for both scientists and developers to identify optimal use cases for each model.
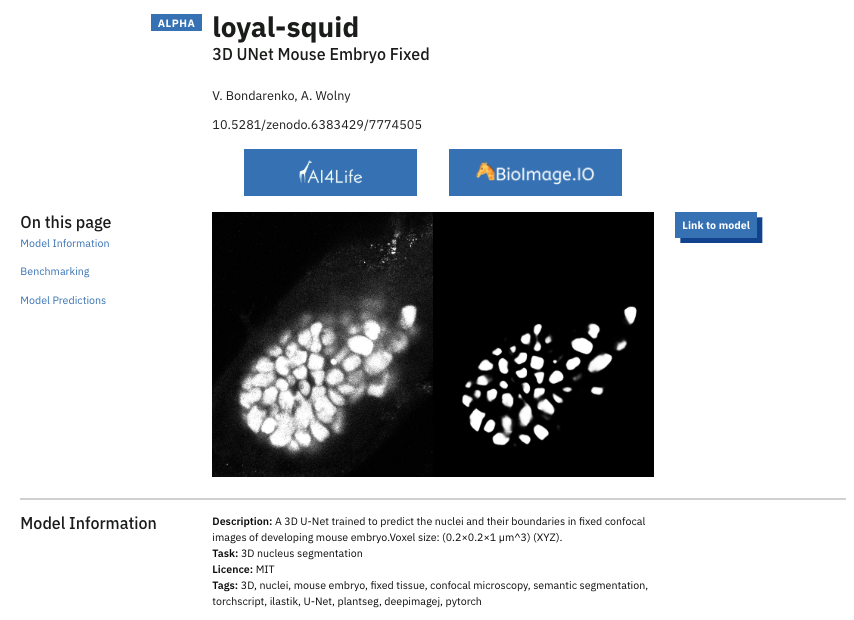
When you navigate to either the “Analysed Datasets” or the “Model Evaluation Platform”, you will find the models or datasets available within that collection, helping you quickly understand what’s included. From there, you can drill down into individual model or dataset views, which offer more detailed summaries.
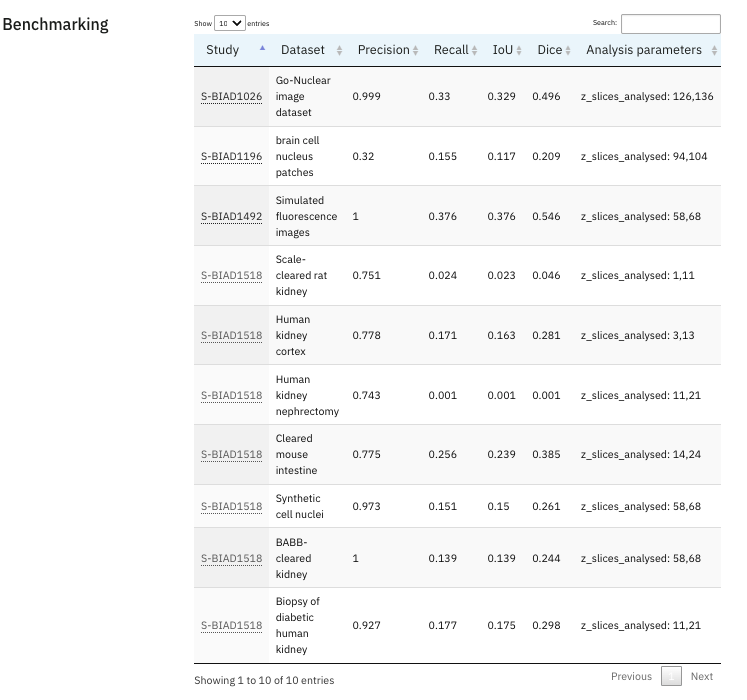
On datasets with available ground truth annotations, you will be able to find metrics—such as precision, recall, Intersection over Union (IoU), and Dice score— that you can use to compare the performance of models.
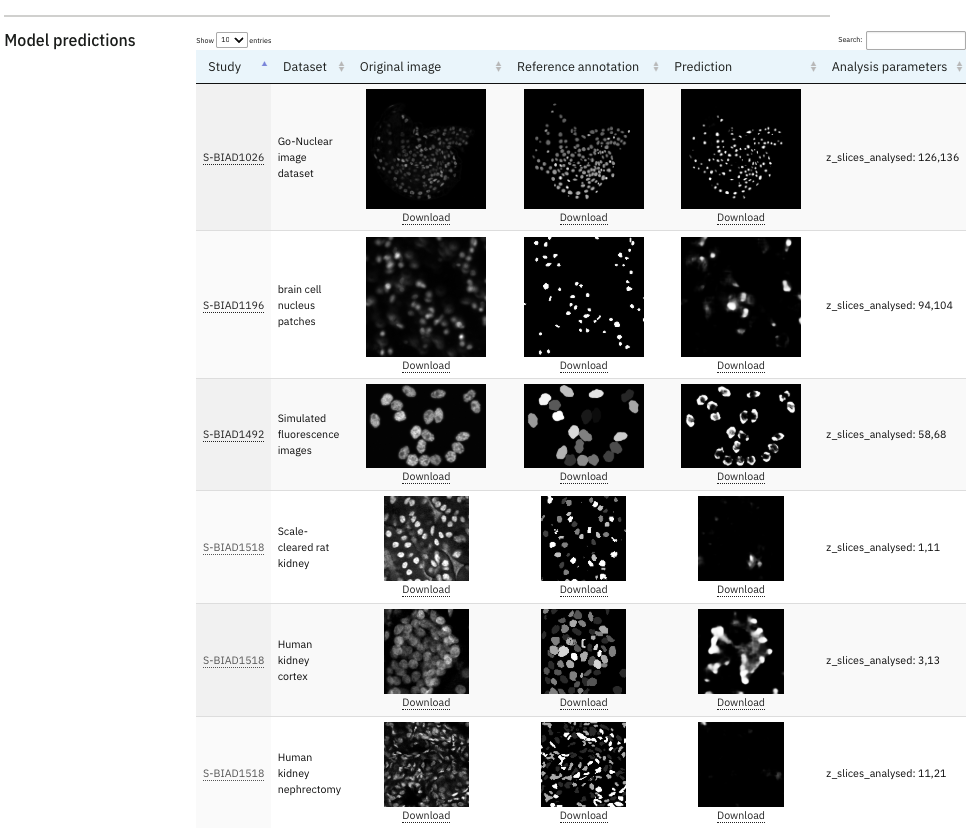
These pages also feature graphical visualisations of model inputs, outputs, and ground truth references—the data used to compute the numerical scores. Input and output images are also available for datasets that do not have ground truth annotations, allowing you to visually inspect the performance of the models.
This Model Evaluation Platform is the first step to achieve our long-term goal to continually increase the utility of the Model Zoo by supporting end-users in selecting appropriate models and enabling developers to benchmark their models against current state-of-the-art approaches with ease.